



Next: クラスター計算
Up: MPI並列化
Previous: MPI並列化
Contents
Index
O(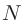 )法は並列化に適したアルゴリズム構造を持っているため、高い並列化効率が期待されます。
典型的なMPIの実行は次の様に行います。
)法は並列化に適したアルゴリズム構造を持っているため、高い並列化効率が期待されます。
典型的なMPIの実行は次の様に行います。
% mpirun -np 4 openmx DIA512_DC.dat > dia512_dc.std &
「work」ディレクトリ中の「DIA512_DC.dat」は、分割統治(DC)法を用いて512個の炭素原子からなるダイヤモンド格子の
SCF計算を実行するための入力ファイルです。MPIプロセス数に対する速度向上比を図 25 (a)に示します。
この並列計算はCRAY-XC30 (Xeonプロセッサ、2.6 GHz) 上で実行し、1MDステップの経過時間から速度向上比が算出
されました。128個のMPIプロセスを用いて、その速度向上は約84倍であり、またプロセス数の増加に伴い、並列化効率は
減少していくことが分かります。並列化効率が減少する理由は、計算負荷の大きなO()対角化計算において
1個のプロセスに割り当てられる原子数が減少し、disk I/Oのような並列化されていない部分の経過時間が顕在化するためです。
また原子種や幾何学構造が一様でない系では、負荷分散が崩れるために並列化効率が大きく減少する場合もあります。
MD計算や分子動力学計算では、動的に負荷分散を保つアルゴリズムが実装されており、可能な限り並列化効率の向上が
図られています。並列化に関するさらなる情報については、「DC-LNO法」と「O() Krylov部分空間法」の章を参照して下さい。
Figure 25:
CRAY-XC30 (Xeonプロセッサ、2.6GHz)上でMPI並列計算を行った場合の、1MDステップの所要時間における速度向上比。
(a) DC法によるダイヤモンド(512炭素原子)の計算、
(b) クラスター法によるMn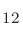 単一分子磁石(148原子)の計算、
(c) バンド法によるダイヤモンド(64炭素原子、3
単一分子磁石(148原子)の計算、
(c) バンド法によるダイヤモンド(64炭素原子、3 33のk点)の計算。
比較のために、理想的な速度向上比に対応する直線も示す。
33のk点)の計算。
比較のために、理想的な速度向上比に対応する直線も示す。
|
|
![\includegraphics[width=8.0cm]{DIA-MPI.eps}](img189.png)