In the current implementation the NEGF calculation is parallelized by MPI. In addition to the MPI parallelization, if you use ACML or MKL, the matrix multiplication and the inverse calculation of matrix in the evaluation of the Green function are also parallelized by OpenMP. In this case, you can perform a hybrid parallelization by OpenMP/MPI which may lead to shorter computational time. The way for the parallelization is completely same as before.
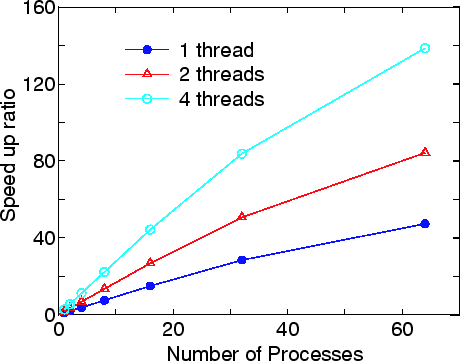
In Fig. 33 we show the speed-up ratio in the elapsed time for the evaluation
of the density matrix of 8-zigzag graphene nanoribbon(ZGNR) under
a finite bias voltage of 0.5 eV. The energy points of 197
(101 and 96 for the equilibrium and nonequilibrium terms,
respectively) are used for the evaluation of the density matrix.
Only the ![]() point is employed for the k-point sampling, and
the spin polarized calculation is performed. Thus, the combination of 394
for the three indices are parallelized by MPI. It is found that the speed-up
ratio of the flat MPI parallelization, corresponding to 1 thread,
reasonably scales up to 64 processes. Furthermore, it can be seen that the
hybrid parallelization, corresponding to 2 and 4 threads, largely improves
the speed-up ratio. By fully using 64 quad core processors, corresponding to
64 processes and 4 threads, the speed-up ratio is about 140, demonstrating
the good scalability of the NEGF method.
For the details see also Ref. [50].
point is employed for the k-point sampling, and
the spin polarized calculation is performed. Thus, the combination of 394
for the three indices are parallelized by MPI. It is found that the speed-up
ratio of the flat MPI parallelization, corresponding to 1 thread,
reasonably scales up to 64 processes. Furthermore, it can be seen that the
hybrid parallelization, corresponding to 2 and 4 threads, largely improves
the speed-up ratio. By fully using 64 quad core processors, corresponding to
64 processes and 4 threads, the speed-up ratio is about 140, demonstrating
the good scalability of the NEGF method.
For the details see also Ref. [50].
 |