



Next: Large-scale calculation
Up: User's manual of OpenMX
Previous: Maximum number of processors
Contents
Index
The OpenMP/MPI hybrid parallel execution can be performed by
% mpirun -np 32 openmx DIA512-1.dat -nt 4 > dia512-1.std &
where '-nt' means the number of threads in each process managed by MPI.
If '-nt' is not specified, then the number of threads is set to 1, which
corresponds to the flat MPI parallelization.
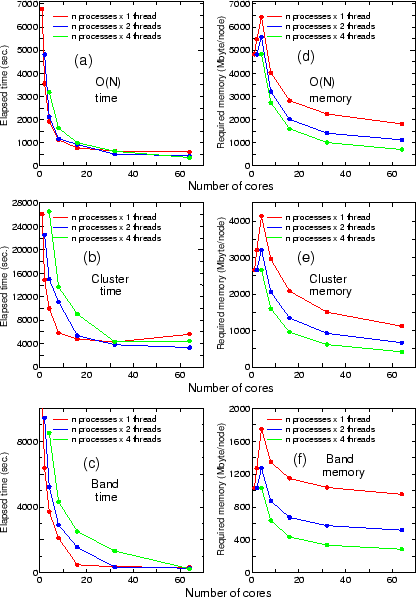
Figure 19 shows
the elapsed time (sec.) and the required memory size (Mbyte) per node
in calculations for the O(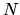 ) Krylov subspace, the cluster, and the
band methods, respectively, where the number of cores is given by
the number of processes by MPI times the number of threads by OpenMP.
As you can see, the hybrid parallelization using 2 or 4 threads is
not fast in the region using the smaller number of processes. However,
the hybrid parallelization gives us the shortest elapsed time
eventually as the number of processes increases. This behavior may be
understood as follows: in the region using the smaller number of processes
the required memory size is large enough so that cash miss easily happens.
This may lead to considerable communication between processor and memory
via bus. So, in the region using the smaller number of processes,
the bus becomes a bottle neck in terms of elapsed time. On the other hand,
in the region using the large number of processes,
the required memory size is small enough that most of data can be stored
in the cashes. So, the efficiency in OpenMP parallelization can be recovered.
In this case, the hybrid parallelization can obtain both the benefits
of MPI and OpenMP. Thus, the hybrid parallelization should be eventually
efficient as the number of processes increases. In fact, our benchmark
calculation may be the case. Also, it should be emphasized that
the required memory size per node can be largely reduced in the hybrid
parallelization in OpenMX as shown in the Fig. 19.
) Krylov subspace, the cluster, and the
band methods, respectively, where the number of cores is given by
the number of processes by MPI times the number of threads by OpenMP.
As you can see, the hybrid parallelization using 2 or 4 threads is
not fast in the region using the smaller number of processes. However,
the hybrid parallelization gives us the shortest elapsed time
eventually as the number of processes increases. This behavior may be
understood as follows: in the region using the smaller number of processes
the required memory size is large enough so that cash miss easily happens.
This may lead to considerable communication between processor and memory
via bus. So, in the region using the smaller number of processes,
the bus becomes a bottle neck in terms of elapsed time. On the other hand,
in the region using the large number of processes,
the required memory size is small enough that most of data can be stored
in the cashes. So, the efficiency in OpenMP parallelization can be recovered.
In this case, the hybrid parallelization can obtain both the benefits
of MPI and OpenMP. Thus, the hybrid parallelization should be eventually
efficient as the number of processes increases. In fact, our benchmark
calculation may be the case. Also, it should be emphasized that
the required memory size per node can be largely reduced in the hybrid
parallelization in OpenMX as shown in the Fig. 19.
Figure 19:
The elapsed time (sec.) and the required memory size (Mbyte) per node
in calculations for (a) and (d) the O() Krylov subspace, (b) and (e)
the cluster, and (c) and (f) the band methods, respectively,
where the number of cores is given by
the number of processes by MPI times the number of threads by OpenMP.
The machine used is an Opteron cluster consisting of two dual core AMD
Opteron (tm) processors 2218, 2.6 GHz, with 8 Gbyte memory per node.
Those nodes are connected with Gbit ether network.
The input files used for those calculations are DIA512-1.dat,
Mn12.dat, and DIA64_Band.dat for the O() Krylov subspace,
the cluster, and the band methods, respectively. They can be found
in the directory 'work'.
 |
Next: Large-scale calculation
Up: User's manual of OpenMX
Previous: Maximum number of processors
Contents
Index
2011-11-10