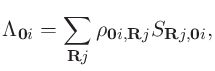DC-LNO法[51]はDC法の改良版です。 占有状態の部分空間を張る局在自然軌道(LNO)を導入することによって、計算効率が改善されます。 本来の基底関数であるPAOと比較してLNOの次元が低減されているため、結果として計算コストが削減されます。 占有状態への射影演算子を局所固有値分解を用いて低ランク近似することで、LNOが生成されます。 このLNO生成する計算は逐次的でないため、非常に効率的に実行可能です。 図 19(a)に示すように、 切られたクラスター(truncated cluster)内の遠方領域の原子に対してLNOが割り当てられ、 また近傍ではPAOを割り当てられます。このため計算精度を保ちながら、計算効率を向上させることが可能となります。 本手法はギャップのある系のみならず、切られたクラスターが十分に大きければ (典型的には200原子以上を含むクラスター)、金属系にも適用可能です。
![\includegraphics[width=16.0cm]{DC-LNO-Fig1.eps}](DC-LNO-Fig1.png)
|
DC-LNO法のオーダー(![]() )計算の最初のステップとして、
ディレクトリworkに置かれた入力ファイルを用いてSi結晶のオーダー(
)計算の最初のステップとして、
ディレクトリworkに置かれた入力ファイルを用いてSi結晶のオーダー(![]() )計算を以下のように実行できます。
)計算を以下のように実行できます。
% mpirun -np 112 ./openmx Si8-LNO.dat | tee si8-lno.std
この計算はXeonクラスター計算機(2.6 GHz)の112コアを用いて66秒で実行されました。
また用いた入力ファイルはディレクトリ「work」中に「Si8-LNO.dat」として保存されています。
図 19(b)に示すように、原子レベル、スピンレベル、対角化レベルの
三段階の並列化が実装されています。
そのため、例えば1000原子系であれば並列計算において40000 CPUコアまでの加速が期待できます。
1000 原子
scf.dclno.threading on # off|on
ハイブリッド並列では、並列化の最下層である対角化がOpenMPで並列化されます。
この手法の計算の精度と効率は以下のキーワードで制御されます。
orderN.HoppingRanges 7.0 # 7.0 (Ang.)
orderN.LNO.Buffer 0.2 # default = 0.2
orderN.LNO.Occ.Cutoff 0.1 # default = 0.1
キーワード「orderN.HoppingRanges」の役割はDC法でのそれと同一です。
各原子に対する切られたクラスターはキーワード「orderN.HoppingRanges」で指定された
半径の球内部の原子から構成されます。
本パラメタの適切な選択は系によりますが、一連のベンチマーク計算からは
300原子を含むように「orderN.HoppingRanges」を設定した場合には
金属系に対しても十分な精度が確保されることが分かっています。
<Definition.of.Atomic.Species
Si Si7.0-s2p2d1 Si_PBE19
H H6.0-s2p1 H_PBE19
Definition.of.Atomic.Species>
LNOの数は以下の様に指定できます。
<LNOs.Num
Si 4
H 1
LNOs.Num>
この場合、LNOの数はSiで4、Hで1にそれぞれ固定されます。
構造最適化や分子動力学シミュレーションの際にLNO数の変化を避けるため
「orderN.LNO.Occ.Cutoff」よりも「LNOs.Num」の使用が推奨されます。
DC法とDC-LNO法の比較を図 20に示します。
DC-LNO法ではクラスター内の遠方領域においてPAOの代わりにLNOが使用されていますが、
ギャップのある系と金属系の両方においてその精度はDC法に匹敵することが分かります。
![\includegraphics[width=15.9cm]{DC-LNO-Fig2.eps}](img175.png)
|
またDC-LNO法の応用例として高温の分子動力学シミュレーションで得られたシリコン、
アルミニウム、リチウム、SiO![]() の液体の動径分布関数(RDF)を図 21に示します。
いずれの場合でもDC-LNO法が通常のオーダー
の液体の動径分布関数(RDF)を図 21に示します。
いずれの場合でもDC-LNO法が通常のオーダー![]() 対角化法の結果を良く再現していることが
分かります。また得られたRDFは他の計算結果[52,53,54,55]
とも整合しています。
対角化法の結果を良く再現していることが
分かります。また得られたRDFは他の計算結果[52,53,54,55]
とも整合しています。
![\includegraphics[width=14.0cm]{DC-LNO-Fig3.eps}](img181.png)
|
DC-LNO法のMPI並列計算における速度向上比を図 22に示します。
これはダイアモンド(64原子を含むスーパーセル)の非スピン分極計算の結果です。
スピンインデックスの多重度は1のため、原子レベルの並列化の最大並列数である
64MPIプロセスまでほぼ理想的な振る舞いが見られます。
64MPIプロセスを超えると原子レベルでの並列化に加えて対角化の並列化が考慮されます。
128と256のMPIプロセスを用いた場合には理想的な速度向上比を超えたスピードアップが観測されました。
これはメモリ使用の削減によりキャッシュの効率的な利用によると推定されます。
本ベンチマーク計算で用いた最大の1280 MPIプロセスまで良いスケーリングが達成されています。
1 MPIプロセスでの経過時間を基準として算出された並列化効率はおよそ70%です。
本ベンチマーク計算で使用したPCクラスターの各計算ノードは20CPUコアから構成されるため、
1280 (=64![]() 20) MPIプロセスまで良いスケーリングが見られることは妥当な結果です。
近年の超並列計算機の発展に伴って、多階層並列化は計算時間を短縮するために
有効な手段であることが分かります。
20) MPIプロセスまで良いスケーリングが見られることは妥当な結果です。
近年の超並列計算機の発展に伴って、多階層並列化は計算時間を短縮するために
有効な手段であることが分かります。
![\includegraphics[width=11.5cm]{DC-LNO-Fig4.eps}](img182.png)
|