大規模計算のために数値的に厳密な低次スケーリング法がサポートされています [80]。
この方法の計算量は、![]() を基底関数の数とすると、1、2、3次元の系に対してそれぞれO(
を基底関数の数とすると、1、2、3次元の系に対してそれぞれO(
![]() )、O(
)、O(![]() )、O(
)、O(![]() )として増加します。
O(
)として増加します。
O(![]() )法と異なり、本方法は低次のスケーリングにも関らず通常のO(
)法と異なり、本方法は低次のスケーリングにも関らず通常のO(![]() )対角化法と同じく数値的に厳密な方法であり、
一つの理論的な枠組で絶縁体から金属にも適用可能です。
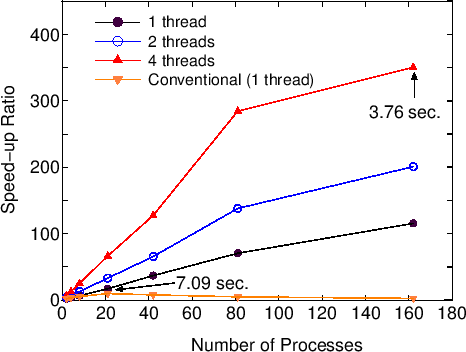
計算のデータ構造が適切に区分けされているため、図36に示すように大規模な並列処理に適しています。
しかし計算量の前因子が大きくなるため、並列計算において多数のCPUコアを使用した場合にのみに、この方法が有利になります。
多数のCPUコアを使って低次元の大規模系を計算する場合、この方法は適切な選択となるでしょう。
この方法を選択するには、キーワード「scf.EigenvalueSolver」を以下の様に指定します。
)対角化法と同じく数値的に厳密な方法であり、
一つの理論的な枠組で絶縁体から金属にも適用可能です。
計算のデータ構造が適切に区分けされているため、図36に示すように大規模な並列処理に適しています。
しかし計算量の前因子が大きくなるため、並列計算において多数のCPUコアを使用した場合にのみに、この方法が有利になります。
多数のCPUコアを使って低次元の大規模系を計算する場合、この方法は適切な選択となるでしょう。
この方法を選択するには、キーワード「scf.EigenvalueSolver」を以下の様に指定します。
scf.EigenvalueSolver cluster2
本手法は、クラスター計算あるいはブリルアンゾーンでのサンプリングに対して![]() 点だけが考慮された周期系のコリニアDFT計算に対してのみ
サポートされています。全エネルギー計算ばかりでなく、力の計算も実装されていますので、幾何学構造の最適化を行うことができます。
しかし状態密度計算や波動関数の計算は実装されていません。周回積分の極の数 [55]は次のキーワードで設定します。
点だけが考慮された周期系のコリニアDFT計算に対してのみ
サポートされています。全エネルギー計算ばかりでなく、力の計算も実装されていますので、幾何学構造の最適化を行うことができます。
しかし状態密度計算や波動関数の計算は実装されていません。周回積分の極の数 [55]は次のキーワードで設定します。
scf.Npoles.ON2 90
収束に必要な極の数は系の大きさに依らずに、系のスペクトル半径に依存しています [80]。 電子温度が300K以上の場合には、100の極を用いれば全エネルギーと力は十分に収束します。 例として、「work」ディレクトリ中の入力ファイル「C60_LO.dat」を用いた計算を示します。
% mpirun -np 8 openmx C60_LO.dat
表7に示すように、本法で計算された全エネルギーは、倍精度の範囲内で通常の対角化法とほぼ一致していますが、
一方、計算時間に関しては、従来法と比較し、非常に長い時間を要しています。
計算時間に関し、本法と通常の対角化法の交点は、系の次元にも依りますが並列処理に100個以上のコアを使う場合、
原子数で300程度であると推測されます。
 |
|